Storm 编程模型
一、简介
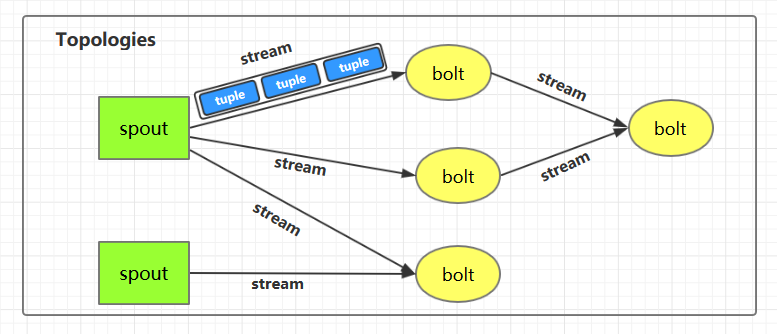
下图为 Strom 的运行流程图,在开发 Storm 流处理程序时,我们需要采用内置或自定义实现 spout(数据源) 和 bolt(处理单元),并通过 TopologyBuilder 将它们之间进行关联,形成 Topology。
二、IComponent接口
IComponent 接口定义了 Topology 中所有组件 (spout/bolt) 的公共方法,自定义的 spout 或 bolt 必须直接或间接实现这个接口。
1 | public interface IComponent extends Serializable { |
三、Spout
3.1 ISpout接口
自定义的 spout 需要实现 ISpout 接口,它定义了 spout 的所有可用方法:
1 | public interface ISpout extends Serializable { |
3.2 BaseRichSpout抽象类
通常情况下,我们实现自定义的 Spout 时不会直接去实现 ISpout 接口,而是继承 BaseRichSpout。BaseRichSpout 继承自 BaseCompont,同时实现了 IRichSpout 接口。
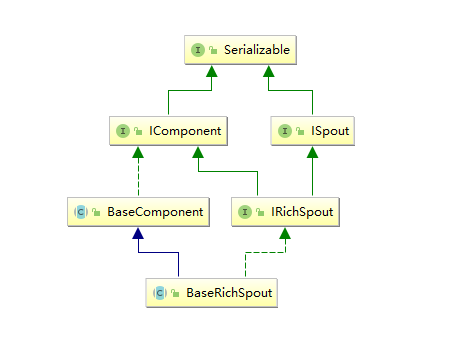
IRichSpout 接口继承自 ISpout 和 IComponent,自身并没有定义任何方法:
1 | public interface IRichSpout extends ISpout, IComponent { |
BaseComponent 抽象类空实现了 IComponent 中 getComponentConfiguration 方法:
1 | public abstract class BaseComponent implements IComponent { |
BaseRichSpout 继承自 BaseCompont 类并实现了 IRichSpout 接口,并且空实现了其中部分方法:
1 | public abstract class BaseRichSpout extends BaseComponent implements IRichSpout { |
通过这样的设计,我们在继承 BaseRichSpout 实现自定义 spout 时,就只有三个方法必须实现:
- open : 来源于 ISpout,可以通过此方法获取用来发送 tuples 的
SpoutOutputCollector; - nextTuple :来源于 ISpout,必须在此方法内部发送 tuples;
- declareOutputFields :来源于 IComponent,声明发送的 tuples 的名称,这样下一个组件才能知道如何接受。
四、Bolt
bolt 接口的设计与 spout 的类似:
4.1 IBolt 接口
1 | /** |
4.2 BaseRichBolt抽象类
同样的,在实现自定义 bolt 时,通常是继承 BaseRichBolt 抽象类来实现。BaseRichBolt 继承自 BaseComponent 抽象类并实现了 IRichBolt 接口。
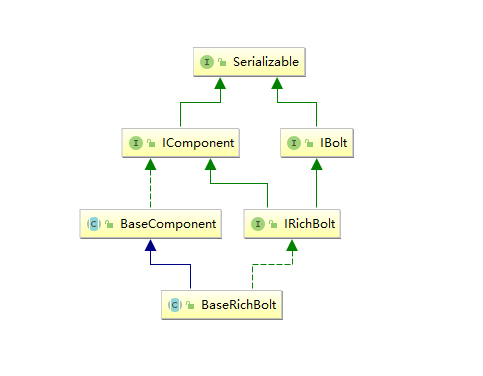
IRichBolt 接口继承自 IBolt 和 IComponent,自身并没有定义任何方法:
1 | public interface IRichBolt extends IBolt, IComponent { |
通过这样的设计,在继承 BaseRichBolt 实现自定义 bolt 时,就只需要实现三个必须的方法:
- prepare: 来源于 IBolt,可以通过此方法获取用来发送 tuples 的
OutputCollector; - execute:来源于 IBolt,处理 tuples 和发送处理完成的 tuples;
- declareOutputFields :来源于 IComponent,声明发送的 tuples 的名称,这样下一个组件才能知道如何接收。
五、词频统计案例
5.1 案例简介
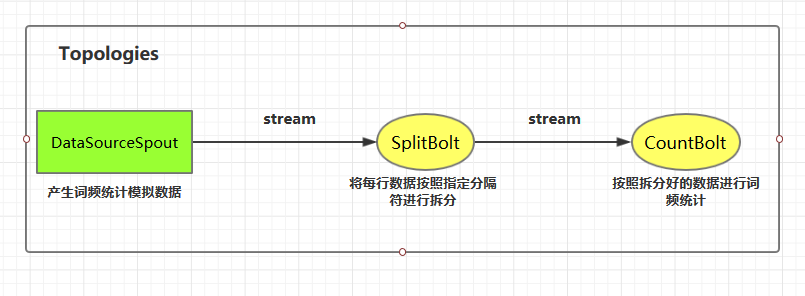
这里我们使用自定义的 DataSourceSpout 产生词频数据,然后使用自定义的 SplitBolt 和 CountBolt 来进行词频统计。
案例源码下载地址:storm-word-count
5.2 代码实现
1. 项目依赖
1 | <dependency> |
2. DataSourceSpout
1 | public class DataSourceSpout extends BaseRichSpout { |
上面类使用 productData 方法来产生模拟数据,产生数据的格式如下:
1 | Spark HBase |
3. SplitBolt
1 | public class SplitBolt extends BaseRichBolt { |
4. CountBolt
1 | public class CountBolt extends BaseRichBolt { |
5. LocalWordCountApp
通过 TopologyBuilder 将上面定义好的组件进行串联形成 Topology,并提交到本地集群(LocalCluster)运行。通常在开发中,可先用本地模式进行测试,测试完成后再提交到服务器集群运行。
1 | public class LocalWordCountApp { |
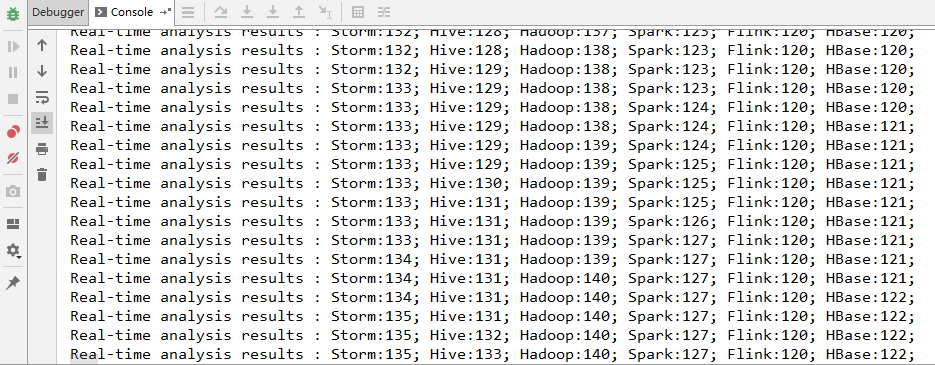
6. 运行结果
启动 WordCountApp 的 main 方法即可运行,采用本地模式 Storm 会自动在本地搭建一个集群,所以启动的过程会稍慢一点,启动成功后即可看到输出日志。
六、提交到服务器集群运行
6.1 代码更改
提交到服务器的代码和本地代码略有不同,提交到服务器集群时需要使用 StormSubmitter 进行提交。主要代码如下:
为了结构清晰,这里新建 ClusterWordCountApp 类来演示集群模式的提交。实际开发中可以将两种模式的代码写在同一个类中,通过外部传参来决定启动何种模式。
1 | public class ClusterWordCountApp { |
6.2 打包上传
打包后上传到服务器任意位置,这里我打包后的名称为 storm-word-count-1.0.jar
1 | mvn clean package -Dmaven.test.skip=true |
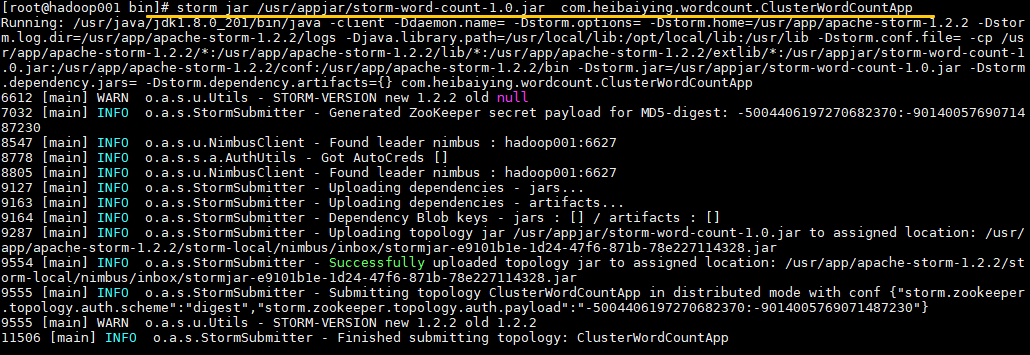
6.3 提交Topology
使用以下命令提交 Topology 到集群:
1 | 命令格式: storm jar jar包位置 主类的全路径 ...可选传参 |
出现 successfully 则代表提交成功:
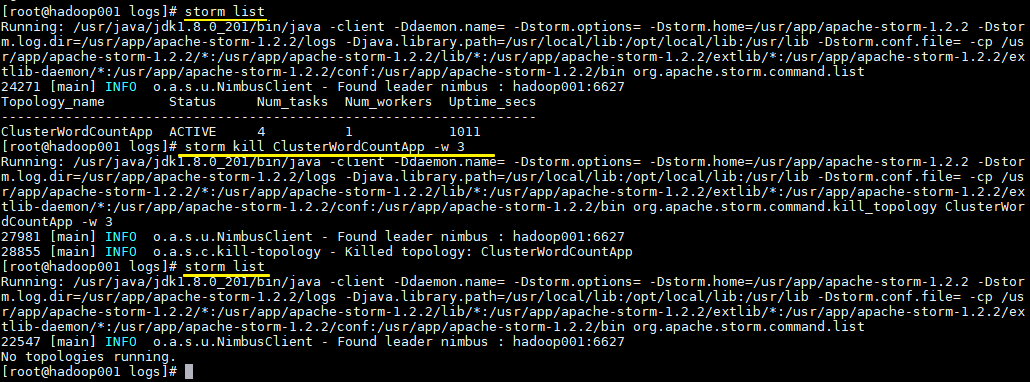
6.4 查看Topology与停止Topology(命令行方式)
1 | 查看所有Topology |
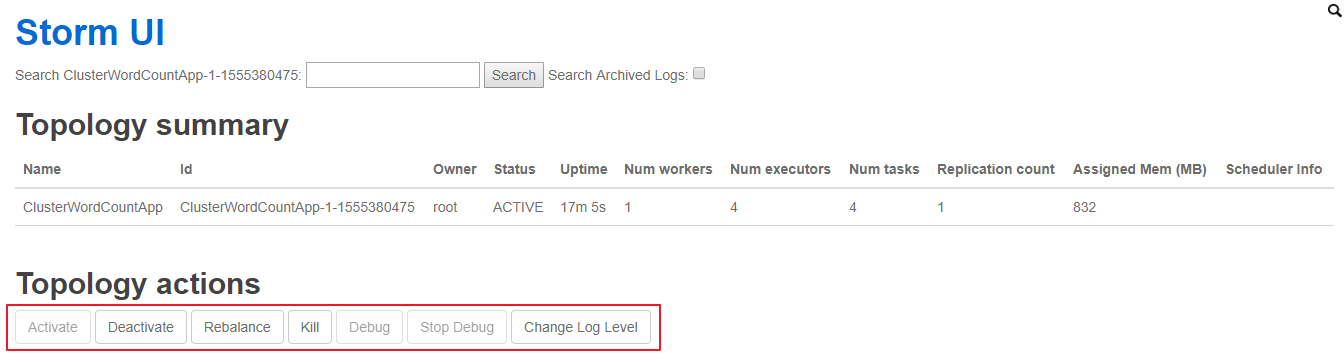
6.5 查看Topology与停止Topology(界面方式)
使用 UI 界面同样也可进行停止操作,进入 WEB UI 界面(8080 端口),在 Topology Summary 中点击对应 Topology 即可进入详情页面进行操作。
七、关于项目打包的扩展说明
mvn package的局限性
在上面的步骤中,我们没有在 POM 中配置任何插件,就直接使用 mvn package 进行项目打包,这对于没有使用外部依赖包的项目是可行的。但如果项目中使用了第三方 JAR 包,就会出现问题,因为 package 打包后的 JAR 中是不含有依赖包的,如果此时你提交到服务器上运行,就会出现找不到第三方依赖的异常。
这时候可能大家会有疑惑,在我们的项目中不是使用了 storm-core 这个依赖吗?其实上面之所以我们能运行成功,是因为在 Storm 的集群环境中提供了这个 JAR 包,在安装目录的 lib 目录下:
为了说明这个问题我在 Maven 中引入了一个第三方的 JAR 包,并修改产生数据的方法:
1 | <dependency> |
StringUtils.join() 这个方法在 commons.lang3 和 storm-core 中都有,原来的代码无需任何更改,只需要在 import 时指明使用 commons.lang3。1 | import org.apache.commons.lang3.StringUtils; |
此时直接使用
mvn clean package 打包运行,就会抛出下图的异常。因此这种直接打包的方式并不适用于实际的开发,因为实际开发中通常都是需要第三方的 JAR 包。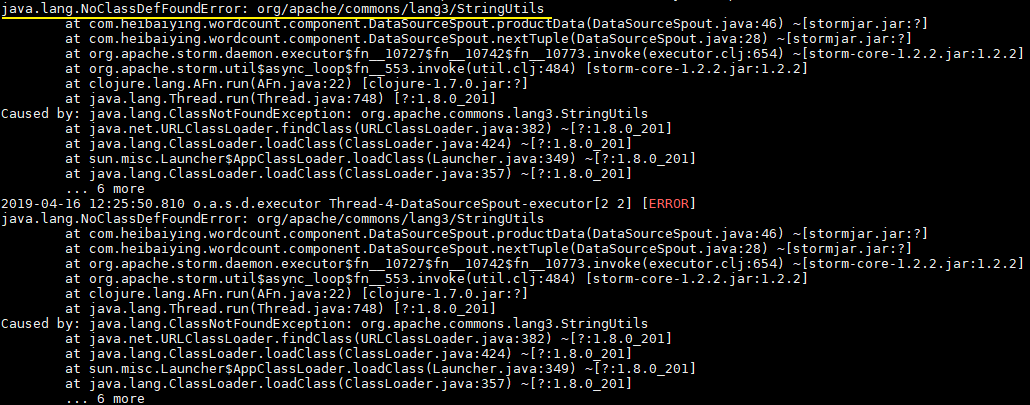
想把依赖包一并打入最后的 JAR 中,maven 提供了两个插件来实现,分别是 maven-assembly-plugin 和 maven-shade-plugin。鉴于本篇文章篇幅已经比较长,且关于 Storm 打包还有很多需要说明的地方,所以关于 Storm 的打包方式单独整理至下一篇文章:

