Storm集成Kafka
一、整合说明
Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下:
- Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持;
- Storm Kafka Integration (0.10.x+) : 包含 Kafka 新版本的 consumer API,主要对 Kafka 0.10.x + 提供整合支持。
这里我服务端安装的 Kafka 版本为 2.2.0(Released Mar 22, 2019) ,按照官方 0.10.x+ 的整合文档进行整合,不适用于 0.8.x 版本的 Kafka。
二、写入数据到Kafka
2.1 项目结构
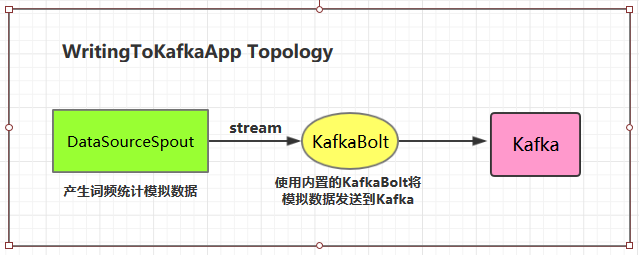
2.2 项目主要依赖
1 | <properties> |
2.3 DataSourceSpout
1 | /** |
产生的模拟数据格式如下:
1 | Spark HBase |
2.4 WritingToKafkaApp
1 | /** |
2.5 测试准备工作
进行测试前需要启动 Kakfa:
1. 启动Kakfa
Kafka 的运行依赖于 zookeeper,需要预先启动,可以启动 Kafka 内置的 zookeeper,也可以启动自己安装的:
1 | zookeeper启动命令 |
启动单节点 kafka 用于测试:
1 | bin/kafka-server-start.sh config/server.properties |
2. 创建topic
1 | 创建用于测试主题 |
3. 启动消费者
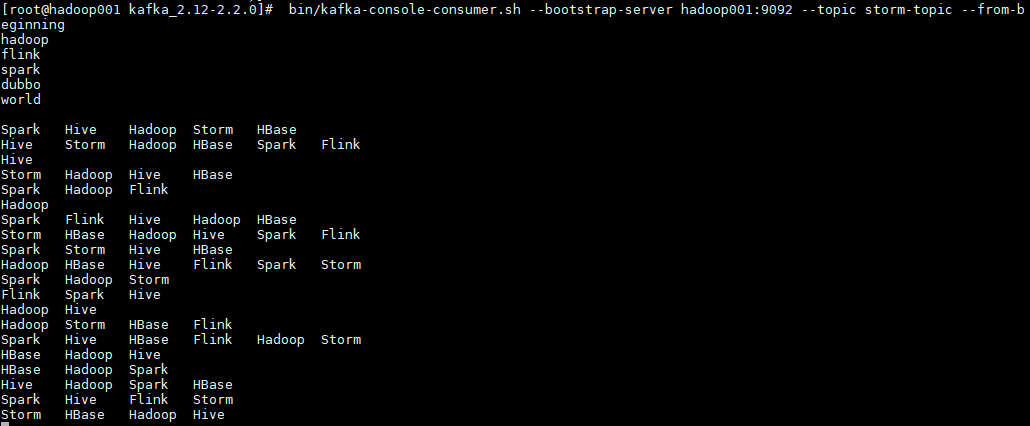
启动一个消费者用于观察写入情况,启动命令如下:
1 | bin/kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic storm-topic --from-beginning |
2.6 测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
1 | mvn clean package -D maven.test.skip=true |
启动后,消费者监听情况如下:
三、从Kafka中读取数据
3.1 项目结构
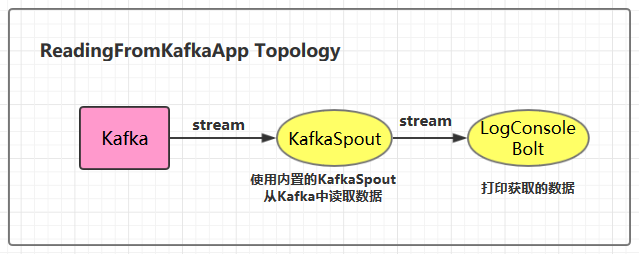
3.2 ReadingFromKafkaApp
1 | /** |
3.3 LogConsoleBolt
1 | /** |
这里从 value 字段中获取 kafka 输出的值数据。
在开发中,我们可以通过继承 RecordTranslator 接口定义了 Kafka 中 Record 与输出流之间的映射关系,可以在构建 KafkaSpoutConfig 的时候通过构造器或者 setRecordTranslator() 方法传入,并最后传递给具体的 KafkaSpout。
默认情况下使用内置的 DefaultRecordTranslator,其源码如下,FIELDS 中 定义了 tuple 中所有可用的字段:主题,分区,偏移量,消息键,值。
1 | public class DefaultRecordTranslator<K, V> implements RecordTranslator<K, V> { |
3.4 启动测试
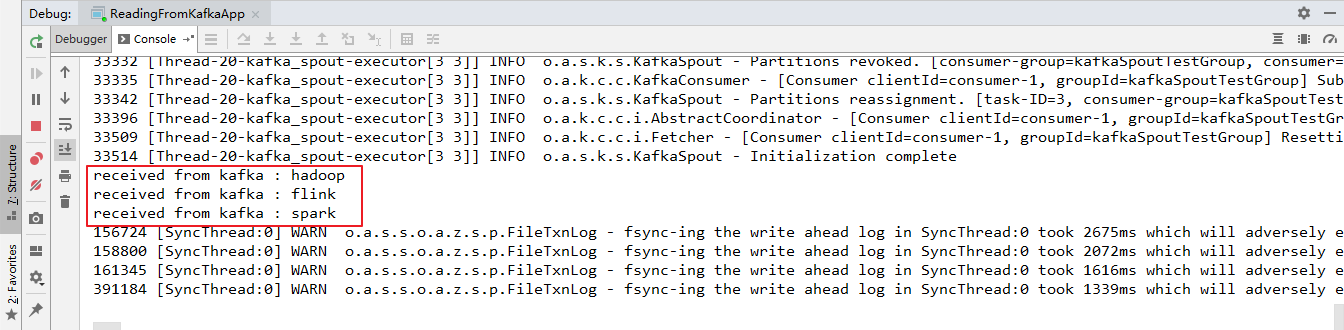
这里启动一个生产者用于发送测试数据,启动命令如下:
1 | bin/kafka-console-producer.sh --broker-list hadoop001:9092 --topic storm-topic |

本地运行的项目接收到从 Kafka 发送过来的数据:
用例源码下载地址:storm-kafka-integration

