Storm集成HDFS和HBase
一、Storm集成HDFS
1.1 项目结构
本用例源码下载地址:storm-hdfs-integration
1.2 项目主要依赖
项目主要依赖如下,有两个地方需要注意:
- 这里由于我服务器上安装的是 CDH 版本的 Hadoop,在导入依赖时引入的也是 CDH 版本的依赖,需要使用
<repository>标签指定 CDH 的仓库地址; hadoop-common、hadoop-client、hadoop-hdfs均需要排除slf4j-log4j12依赖,原因是storm-core中已经有该依赖,不排除的话有 JAR 包冲突的风险;
1 | <properties> |
1.3 DataSourceSpout
1 | /** |
产生的模拟数据格式如下:
1 | Spark HBase |
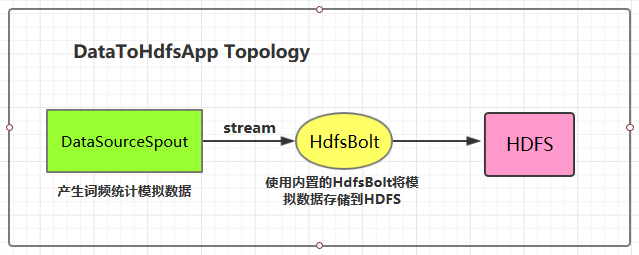
1.4 将数据存储到HDFS
这里 HDFS 的地址和数据存储路径均使用了硬编码,在实际开发中可以通过外部传参指定,这样程序更为灵活。
1 | public class DataToHdfsApp { |
1.5 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
1 | mvn clean package -D maven.test.skip=true |
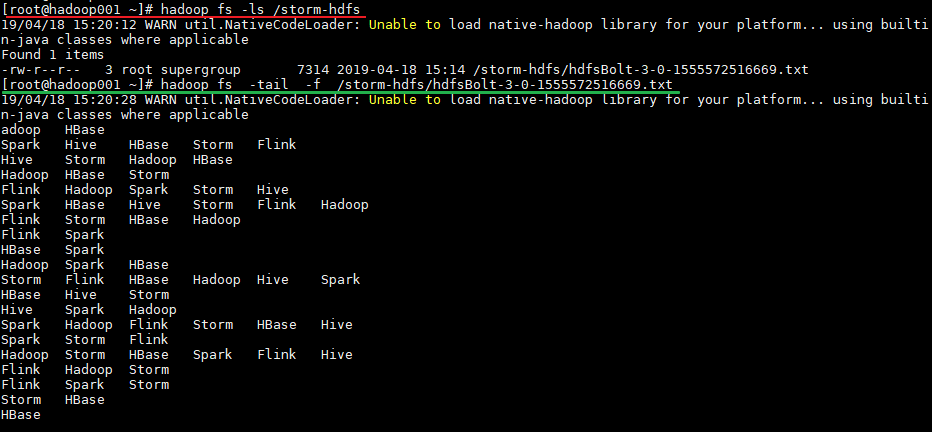
运行后,数据会存储到 HDFS 的 /storm-hdfs 目录下。使用以下命令可以查看目录内容:
1 | 查看目录内容 |
二、Storm集成HBase
2.1 项目结构
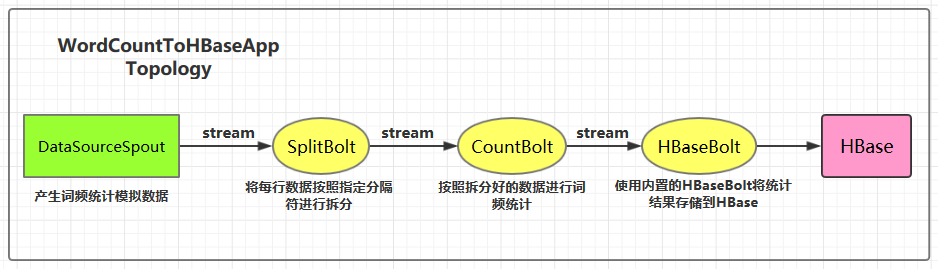
集成用例: 进行词频统计并将最后的结果存储到 HBase,项目主要结构如下:
本用例源码下载地址:storm-hbase-integration
2.2 项目主要依赖
1 | <properties> |
2.3 DataSourceSpout
1 | /** |
产生的模拟数据格式如下:
1 | Spark HBase |
2.4 SplitBolt
1 | /** |
2.5 CountBolt
1 | /** |
2.6 WordCountToHBaseApp
1 | /** |
2.7 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
1 | mvn clean package -D maven.test.skip=true |
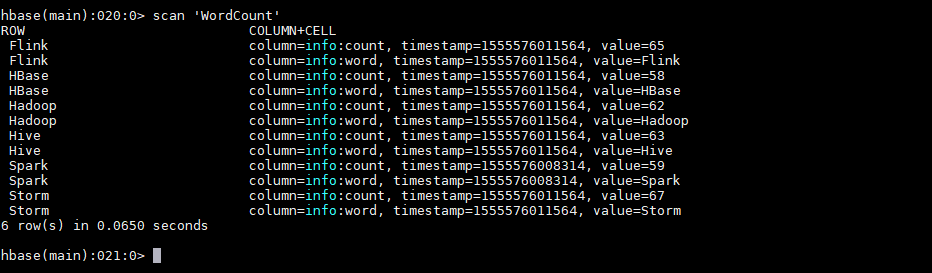
运行后,数据会存储到 HBase 的 WordCount 表中。使用以下命令查看表的内容:
1 | hbase > scan 'WordCount' |
2.8 withCounterFields
在上面的用例中我们是手动编码来实现词频统计,并将最后的结果存储到 HBase 中。其实也可以在构建 SimpleHBaseMapper 的时候通过 withCounterFields 指定 count 字段,被指定的字段会自动进行累加操作,这样也可以实现词频统计。需要注意的是 withCounterFields 指定的字段必须是 Long 类型,不能是 String 类型。
1 | SimpleHBaseMapper mapper = new SimpleHBaseMapper() |

