聚合函数Aggregations
一、简单聚合
1.1 数据准备
1 | // 需要导入 spark sql 内置的函数包 |
注:emp.json 可以从本仓库的resources 目录下载。
1.2 count
1 | // 计算员工人数 |
1.3 countDistinct
1 | // 计算姓名不重复的员工人数 |
1.4 approx_count_distinct
通常在使用大型数据集时,你可能关注的只是近似值而不是准确值,这时可以使用 approx_count_distinct 函数,并可以使用第二个参数指定最大允许误差。
1 | empDF.select(approx_count_distinct ("ename",0.1)).show() |
1.5 first & last
获取 DataFrame 中指定列的第一个值或者最后一个值。
1 | empDF.select(first("ename"),last("job")).show() |
1.6 min & max
获取 DataFrame 中指定列的最小值或者最大值。
1 | empDF.select(min("sal"),max("sal")).show() |
1.7 sum & sumDistinct
求和以及求指定列所有不相同的值的和。
1 | empDF.select(sum("sal")).show() |
1.8 avg
内置的求平均数的函数。
1 | empDF.select(avg("sal")).show() |
1.9 数学函数
Spark SQL 中还支持多种数学聚合函数,用于通常的数学计算,以下是一些常用的例子:
1 | // 1.计算总体方差、均方差、总体标准差、样本标准差 |
1.10 聚合数据到集合
1 | scala> empDF.agg(collect_set("job"), collect_list("ename")).show() |
二、分组聚合
2.1 简单分组
1 | empDF.groupBy("deptno", "job").count().show() |
2.2 分组聚合
1 | empDF.groupBy("deptno").agg(count("ename").alias("人数"), sum("sal").alias("总工资")).show() |
三、自定义聚合函数
Scala 提供了两种自定义聚合函数的方法,分别如下:
- 有类型的自定义聚合函数,主要适用于 DataSet;
- 无类型的自定义聚合函数,主要适用于 DataFrame。
以下分别使用两种方式来自定义一个求平均值的聚合函数,这里以计算员工平均工资为例。两种自定义方式分别如下:
3.1 有类型的自定义函数
1 | import org.apache.spark.sql.expressions.Aggregator |
自定义聚合函数需要实现的方法比较多,这里以绘图的方式来演示其执行流程,以及每个方法的作用:
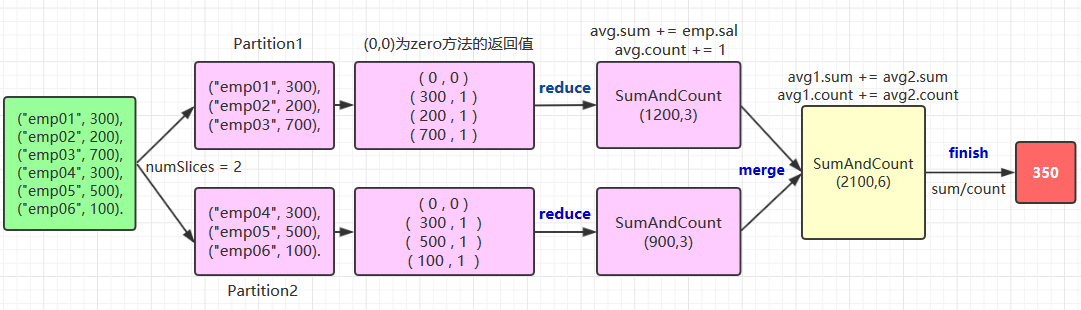
关于 zero,reduce,merge,finish 方法的作用在上图都有说明,这里解释一下中间类型和输出类型的编码转换,这个写法比较固定,基本上就是两种情况:
- 自定义类型 Case Class 或者元组就使用
Encoders.product方法; - 基本类型就使用其对应名称的方法,如
scalaByte,scalaFloat,scalaShort等,示例如下:
1 | override def bufferEncoder: Encoder[SumAndCount] = Encoders.product |
3.2 无类型的自定义聚合函数
理解了有类型的自定义聚合函数后,无类型的定义方式也基本相同,代码如下:
1 | import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction} |
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02

