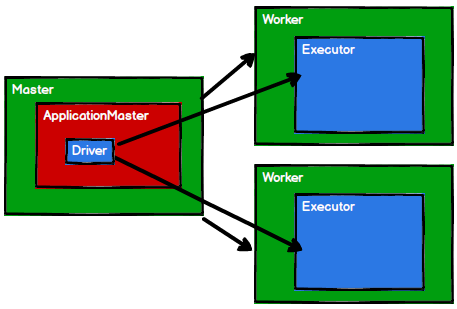
Spark的诞生
一、前提

MapReduce缺点:
MR基于数据集计算,所以是面向数据
1)基本运算规则从存储介质中获取(采集)数据,然后进行计算,最后将结果存储到介质中,所以主要应用于一次性计算,不适合于数据挖掘和机器学习这样的迭代计算和图形挖掘计算
2)MR是基于文件存储介质进行操作的,所以性能非常的慢
3)MR和Hadoop紧密耦合在一起,无法动态获取
二、Spark的诞生
因为MR无法满足对数据的迭代计算,Spark就应运而生
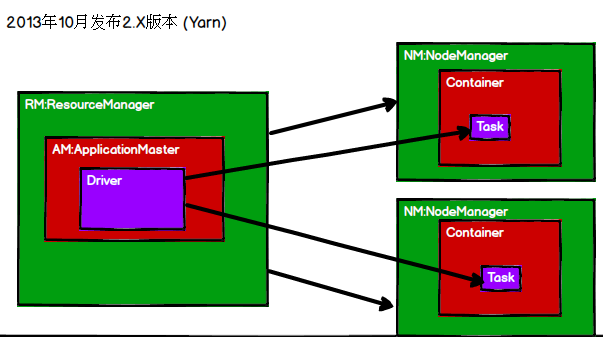
Spark历史
2013年6月发布
Spark基于Hadoop1.X架构思想,采用自己的方式改善Hadoop1.X中的问题
Spark基于内存计算,并且基于Scala语法开发,所以天生适合迭代式计算
Spark只适用于计算,存储还是要使用Hadoop的HDFS,也就是Spark+HDFS,YARN是可以动态的插拔计算框架的(YARN是支持Spark的计算的),通过YARN连接Spark和Hadoop结合使用