MapReduce案例实操
1、MapReduce核心编程思想
1)分布式的运算程序往往需要分成至少2个阶段
2)第一个阶段的maptask并发实例,完全并行运行,互不相干
3)第二个阶段的reduce task并发实例互不相干,但是他们的数据依赖于上一个阶段的所有maptask并发实例的输出
4)MapReduce编程模型只能包含一个map阶段和一个reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个mapreduce程序,串行运行
2、MapReduce程序运行流程详解
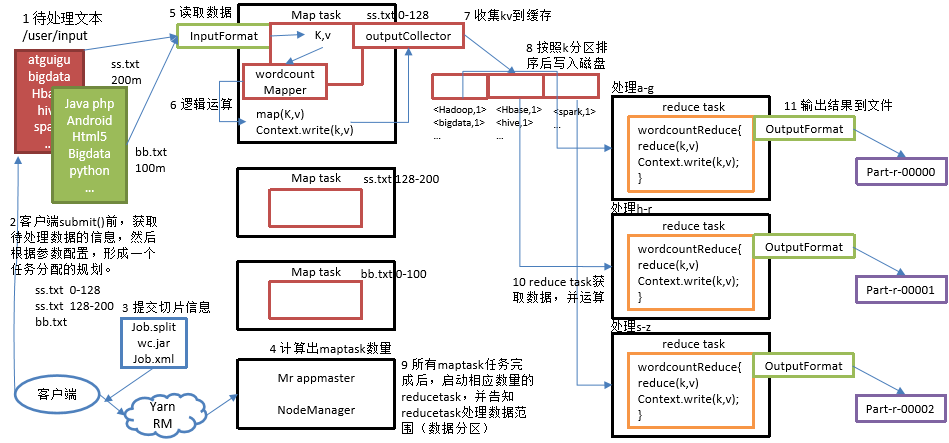
MR程序具体运行步骤如下:
1)在MapReduce程序读取文件的输入目录上存放相应的文件。
2)客户端程序在submit()方法执行前,获取待处理的数据信息,然后根据集群中参数的配置形成一个任务分配规划。
3)客户端提交job.split、jar包、job.xml等文件给yarn,yarn中的resourcemanager启动MRAppMaster。
4)MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程。
5)maptask利用客户指定的inputformat来读取数据,形成输入KV对。
6)maptask将输入KV对传递给客户定义的map()方法,做逻辑运算。
7)map()运算完毕后将KV对收集到maptask缓存。
8)maptask缓存中的KV对按照K分区排序后不断写到磁盘文件。
9)MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据分区。
10)Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算。
11)Reducetask运算完毕后,调用客户指定的outputformat将结果数据输出到外部存储。
3、案例实践
新建Maven工程,在pom.xml文件中添加依赖1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183 <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
```
在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
```xml
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
```
### 3.1、WordCount案例
需求:在给定的文本文件中统计输出每一个单词出现的总次数
输入数据:
```xml
hello world
hadoop
spark
hello world
hadoop
spark
hello world
hadoop
spark
```
**代码**:
1)**定义一个mapper类**
```java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* (1)用户自定义的Mapper要继承自己的父类
* (2)Mapper的输入数据是K-V对的形式(K-V的类型可自定义)
* (3)Mapper中的业务逻辑写在map()方法中
* (4)Mapper的输出数据是K-V对的形式(K-V的类型可自定义)
* (5)map()方法(maptask进程)对每一个<K,V>调用一次
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* map()方法(maptask进程)对每一个<K,V>调用一次
*
* @param key : 数据的offset
* @param value : 要处理的一行数据
* @param context : 上下文
* @throws IOException
* @throws InterruptedException
*/
IntWritable v = new IntWritable(1);
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、获取一行数据,将一行数据转化为String类型
String line = value.toString();
//2、切割
String[] words = line.split(" ");
//3、循环写出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
```
2)**定义一个reducer类**
```java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* (1)用户自定义的Reducer要继承自己的父类
* (2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
* (3)Reducer的业务逻辑写在reduce()方法中
* (4)Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法
*/
public class WordcountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法
*
* @param key : 单词
* @param values : 单词个数(1)的集合
* @param context : 上下文
* @throws IOException
* @throws InterruptedException
*/
IntWritable v = new IntWritable();
int sum;
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//1、累加
sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
//2、写出
v.set(sum);
context.write(key, v);
}
}
```
3)**定义一个主类,用来描述job并提交job**
```java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 相当于yarn客户端,负责提交MapReduce程序
*/
public class WordcountDriver {
public static void main(String[] args) throws Exception {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(WordcountDriver.class);
// 3 设置map和reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReduce.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置Reduce输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置job数据输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
```
第一种情况:
设置好job数据输入和输出路径,直接在IDEA上运行代码,得到输出结果即可。
第二种情况:
在IDEA上打包成jar,上传到集群上运行
运行命令:
```xml
hadoop jar mapreduce-1.0-SNAPSHOT.jar com.atguigu.wordcount.WordcountDriver /user/atguigu/wc/input/hello.txt /user/atguigu/wc/output
hadoop jar jar包名称 Driver类 数据输入路径 数据输出路径
得到输出结果即可。
3.2、数据清洗案例
需求:去除日志中字段长度小于等于11的日志。
输入数据:
数据源
期望输出数据:
每行字段长度都大于11。(实际通过计数器计数:符合要求的为true,不符合的为false)
需求分析:
需要在Map阶段对输入的数据根据规则进行过滤清洗。
代码:
1)编写LogParseMapper类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogParseMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
Text k = new Text();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
boolean result = LogParse(line, context);
if (!result) {
return;
}
k.set(line);
context.write(k, NullWritable.get());
}
private boolean LogParse(String line, Context context) {
String[] fields = line.split(" ");
if (fields.length > 11) {
context.getCounter("map", "true").increment(1);
return true;
}
context.getCounter("map", "false").increment(1);
return false;
}
}
2)编写LogParseDriver类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogParseDriver {
public static void main(String[] args) throws Exception {
//输入输出路径需要根据自己
##### web.log
```code
194.237.142.21 - - [18/Sep/2013:06:49:18 +0000] "GET /wp-content/uploads/2013/07/rstudio-git3.png HTTP/1.1" 304 0 "-" "Mozilla/4.0 (compatible;)"
183.49.46.228 - - [18/Sep/2013:06:49:23 +0000] "-" 400 0 "-" "-"
163.177.71.12 - - [18/Sep/2013:06:49:33 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
163.177.71.12 - - [18/Sep/2013:06:49:36 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:49:42 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:49:45 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
60.208.6.156 - - [18/Sep/2013:06:49:48 +0000] "GET /wp-content/uploads/2013/07/rcassandra.png HTTP/1.0" 200 185524 "http://cos.name/category/software/packages/" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
222.68.172.190 - - [18/Sep/2013:06:50:08 +0000] "-" 400 0 "-" "-"
183.195.232.138 - - [18/Sep/2013:06:50:16 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
183.195.232.138 - - [18/Sep/2013:06:50:16 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
66.249.66.84 - - [18/Sep/2013:06:50:28 +0000] "GET /page/6/ HTTP/1.1" 200 27777 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
221.130.41.168 - - [18/Sep/2013:06:50:37 +0000] "GET /feed/ HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
157.55.35.40 - - [18/Sep/2013:06:51:13 +0000] "GET /robots.txt HTTP/1.1" 200 150 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)"
50.116.27.194 - - [18/Sep/2013:06:51:35 +0000] "POST /wp-cron.php?doing_wp_cron=1379487095.2510800361633300781250 HTTP/1.0" 200 0 "-" "WordPress/3.6; http://blog.fens.me"
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /nodejs-socketio-chat/ HTTP/1.1" 200 10818 "http://www.google.com/url?sa=t&rct=j&q=nodejs%20%E5%BC%82%E6%AD%A5%E5%B9%BF%E6%92%AD&source=web&cd=1&cad=rja&ved=0CCgQFjAA&url=%68%74%74%70%3a%2f%2f%62%6c%6f%67%2e%66%65%6e%73%2e%6d%65%2f%6e%6f%64%65%6a%73%2d%73%6f%63%6b%65%74%69%6f%2d%63%68%61%74%2f&ei=rko5UrylAefOiAe7_IGQBw&usg=AFQjCNG6YWoZsJ_bSj8kTnMHcH51hYQkAA&bvm=bv.52288139,d.aGc" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:36 +0000] "GET /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"

